
前回、RAGについて簡単に解説しました。
今回はローカル環境にRAGを実際に構築してみたいと思います。
<本記事のゴール>
LlamaIndex+Ollamaでファイルから検索・回答できる環境を作る
インストール
RAG環境を構築するにあたって、下記のものが必要になります。
Pythonのインストールについては割愛します。
Ollamaについてはこちらの記事をご参照ください。

Ollamaのセットアップ後、追加のライブラリをインストールします。
ollama pull nomic-embed-text必要であればPythonの仮想環境を作成しておきます。
python -m venv .venv && source .venv/bin/activate # Windowsの場合: .venv\Scripts\activate最後にLlamaIndexをインストールを行います。
LlamaIndexはPythonライブラリのため、こちらをインストールします。
pip install llama-index llama-index-llms-ollama llama-index-embeddings-ollama llama-index-readers-file以上で必要なものは揃いました。非常に簡単ですね。
実行ソース
LlamaIndexを実行するソースです。
# run.py
import os
from pathlib import Path
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
Settings,
load_index_from_storage,
)
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
OLLAMA_BASE = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434")
GEN_MODEL = os.getenv("OLLAMA_MODEL", "gpt-oss:20b") #使用するモデル
EMB_MODEL = os.getenv("OLLAMA_EMBED_MODEL", "nomic-embed-text")
def _setup_services():
Settings.llm = Ollama(model=GEN_MODEL, base_url=OLLAMA_BASE, request_timeout=600.0)
Settings.embed_model = OllamaEmbedding(model_name=EMB_MODEL, base_url=OLLAMA_BASE)
def build_or_load_index(data_dir="data", persist_dir="storage"):
_setup_services()
docstore_path = os.path.join(persist_dir, "docstore.json")
# 既存があればロード
if os.path.exists(docstore_path):
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
return load_index_from_storage(storage_context)
reader = SimpleDirectoryReader(
input_dir=data_dir,
recursive=True,
)
docs = reader.load_data()
if not docs:
raise RuntimeError(f"No documents loaded from: {data_dir}. Check file paths/permissions.")
# 新規作成時は persist_dir を渡さない
storage_context = StorageContext.from_defaults()
index = VectorStoreIndex.from_documents(docs, storage_context=storage_context, show_progress=True)
# ここで永続化
os.makedirs(persist_dir, exist_ok=True)
index.storage_context.persist(persist_dir=persist_dir)
return index
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="LlamaIndex × Ollama RAG")
parser.add_argument("--query", required=True)
parser.add_argument("--topk", type=int, default=5)
parser.add_argument("--data_dir", default="data")
parser.add_argument("--persist_dir", default="storage")
args = parser.parse_args()
index = build_or_load_index(args.data_dir, args.persist_dir)
query_engine = index.as_query_engine(similarity_top_k=args.topk, response_mode="compact")
resp = query_engine.query(args.query)
print("\n[Answer]\n", str(resp))
print("\n-- Sources --")
for s in resp.source_nodes:
name = s.node.metadata.get("file_name") or s.node.metadata.get("source") or ""
preview = s.node.get_text()[:120].replace("\n", " ")
print(f"- score={s.score:.3f} | {name} | {preview}...")
最初は格納されたファイルをベクトル化して保存し、以降は保存されたベクトルデータをロードします。
その後、質問をベクトル化して近似データを検索し、LLMに投げるといった流れになっています。
フォルダ構成
最終的なフォルダ構成です。
rag-sample/
├─ data/ # ここに検索対象のファイル(PDF/TXT/MDなど)を置く
│ ├─ manual.pdf
│ └─ faq.md
├─ storage/ # ベクトルDB等の永続化先(自動生成)
└─ run.py「data」フォルダに検索対象のファイルを格納しておきます。
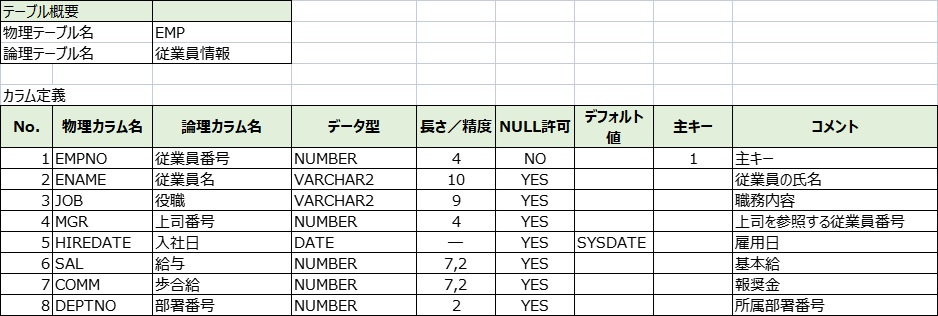
今回は下記のテーブル定義を入れておきました。
実行
下記のコマンドで実行します。
python run.py --query "質問内容"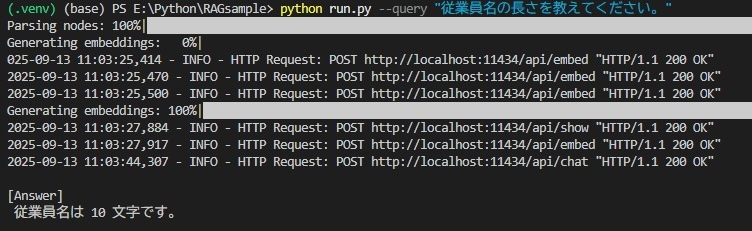
「data」フォルダに格納しておいたファイルの内容で回答してくれましたね。
まとめ
コードを少し書きますが、簡単にRAGの構築ができました。
ファイルをベクトル化する際、マシンスペックやファイルサイズ、ファイル数によっては、結構時間がかかる場合があるのでご注意ください。
回答精度が良くない場合は、モデルの変更やファイル内容の整理、プロンプトの工夫などで改善する可能性があります。
ファイルが多くレスポンスが悪い場合は、ベクトルDBを使って高速化させることもできます。
手軽に試し状況に応じて拡張もでき、ローカル環境のためスモールスタートに最適です。
次のステップとして
・外部DB参照
・ハイブリッドRAG
・API化
など様々あるので、また別の機会に試してみたいと思います。


コメント